Tickle.py Dev Diary #6

Above: A still from Aeon Flux Season 3, Episode 4: A Last Time For Everything (1995)
Hello and welcome to another dev diary, in this one we will be comparing and ranking the different training models to find the one that we like best!
I made the decision to run epoch 12 on my local computer as that was the highest epoch where I could personally perceive ASMR triggers. That was a mistake as the data was overfitted and I ended up wasting a bunch of time.
Our training process saved models every 2 epochs so in total we have 5 usable models.
e2
e4
e6
e8
e10
After generating some outputs for e10 it clearly suffers from the same overfitting issues as e12, which takes us down to 4 usable models.
The model generating a clip that can be considered ASMR is mostly a coin flip and does not appear to be dependant on epoch for example looking at e8:
The above clip is very clearly a “success”, however lets look at some other outputs from the same model:
These are not successful as they are too quiet and have little to no audible content.
Lets compare the spectrographs to see if there is anything going on:
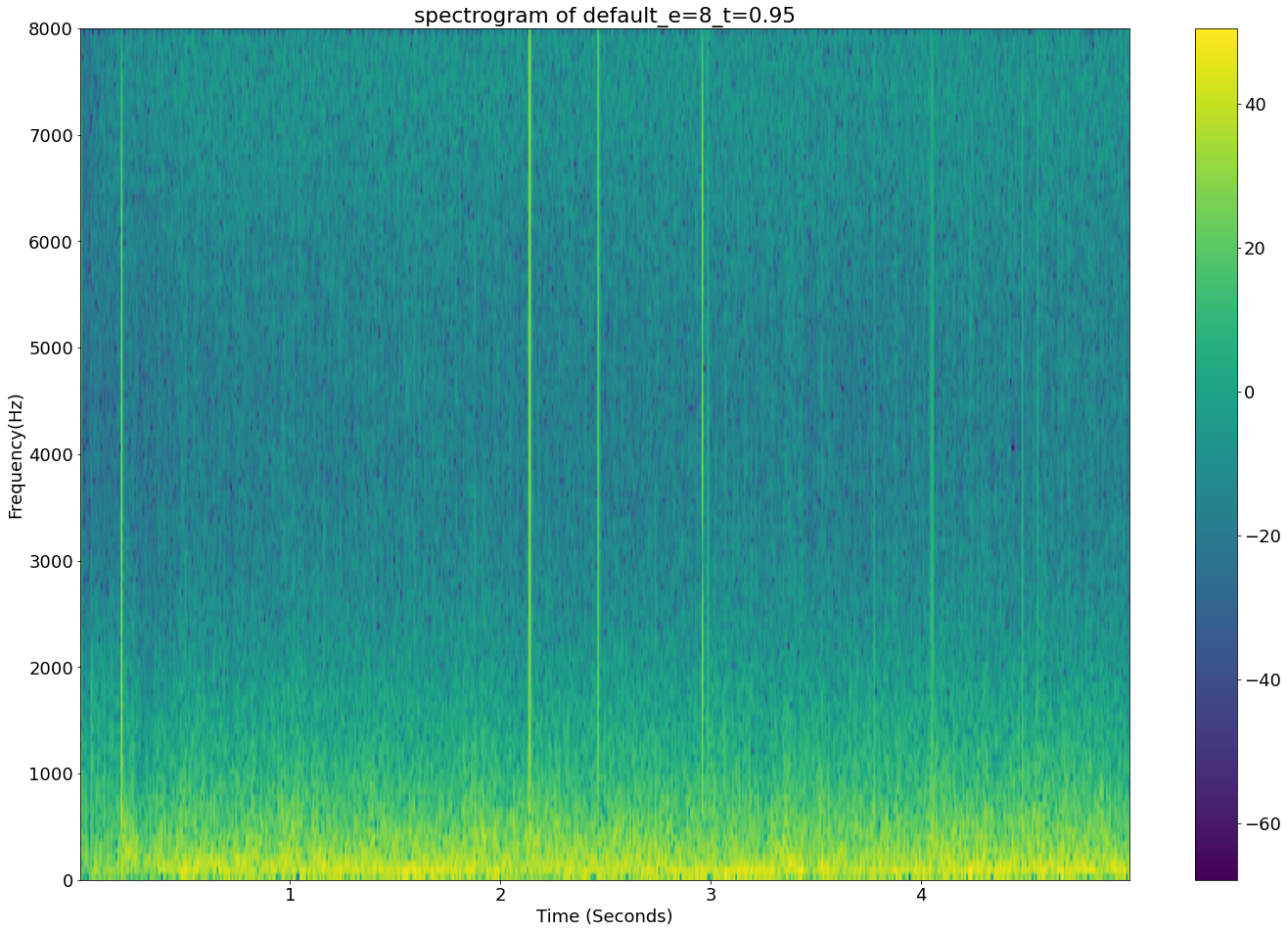
Above: A Spectogram of a “successful” output
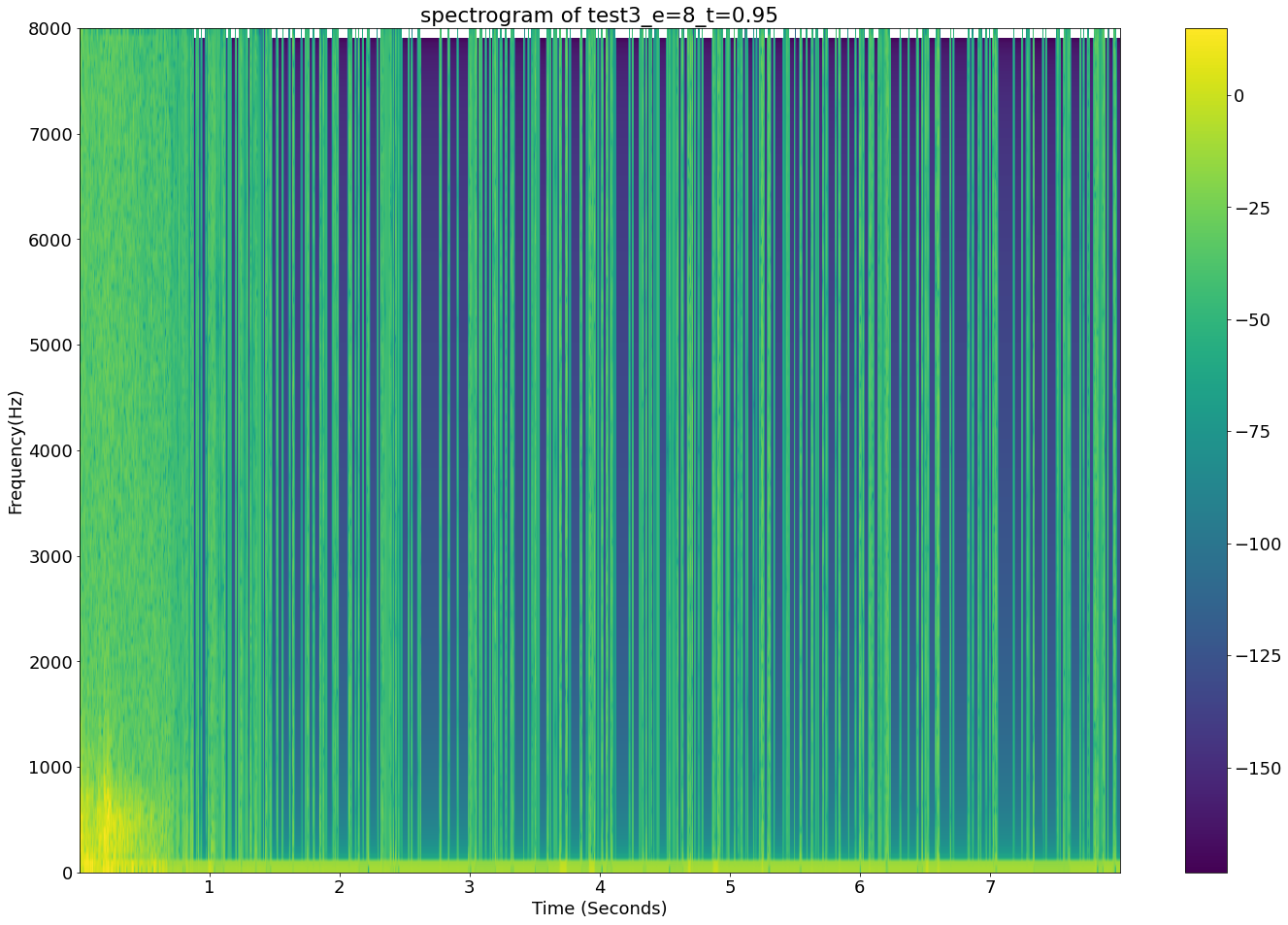
Above: A spectrogram of an “unsuccessful” output, note the vertical artefacts
It seems that all of the “unsuccessful” outputs have similar vertical audio artefacts.
Looking at how clear the ASMR clicks are shown in the “successful” spectrograph as vertical impulses, perhaps the artefacts are a result of the model trying to replicate the ASMR clicks and overshooting?
Could this be Tensorflow confusing the ASMR content for noise and applying a noise suppression filter?
Would it be possible to fix the model by artificially ‘filling in’ the artefacts with nonzero data?
In any case it appears that for the time being careful curation of audio outputs and manually choosing successful outputs is the best option for now.
Surprisingly, past the overfit point of e12 where the artefacts become overly common the length that the model has been trained does not seem to have much impact on the quality of the sound that is generated other than clicks are generally more pronounced within the higher numbered models and there is more low pitched rumbling and noise in the lower numbered ones. Potentially, this could be turned into a feature allowing us some control over the triggers that the model generates.
In the end I think the most important thing now is to either figure out why the artefacts are happening or find a way to work around them (Manual Curation). As I do not have the time to train my model again I will pick manual curation for now but I think that this is a very big area for improvement and solving this would improve the perceived effectiveness and usability of my model significantly.