Tickle.py Dev Diary #5

Above: Archival footage of me rising from my coronavirus coma (its actually from a legacy of kain: blood omen 2 mod)
Long time no see! Long story short, I caught coronavirus and it put a spanner in my plans for quite some time but now i’m better and ready to get back to putting the finishing touches on Tickle.py!
In our last blog I finally got my model producing sound and my next steps would be to wrap and adapt the sound generation script into something slightly more user friendly than it currently is.
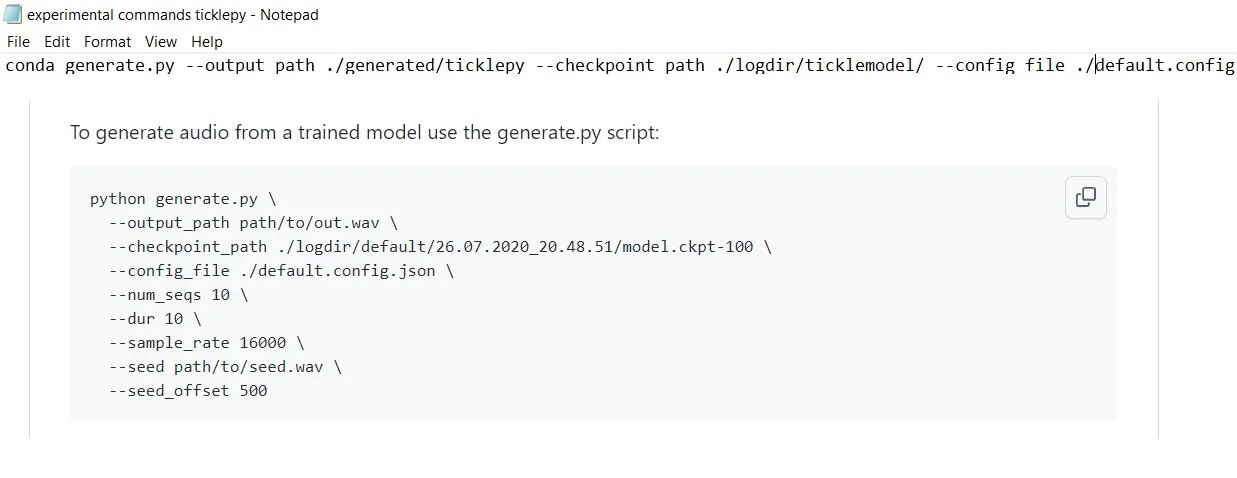
Above: the commands above are from the prism-samplRNN generate.py script I want to simplify this process a bit in tickle.py
My plan at the moment is to edit some of the generate code using the argparse module to reduce the amount of commands required, mostly this will be done by setting default values for the variables. I might do a few experiments with the seed audio functionality built into the prism script later on down the line but this is not a main priority for the immediate future.
AND NOW FOR THE LOCAL ENVIRONMENT TESTS

Above: Running into issues downloading dependencies for running my script locally.
As part of this project was to see if I could run this locally I made an attempt to run the TensorFlow generation model directly on my computer before creating the python wrapper to make sure that this is feasible. I then ran into some issues with my local computers anaconda environment, however thanks to a helpful github user I managed to solve my python issues!

Above: Github user deduble commenting the solution for my issue with my local environment with the TensorFlow library
With this and downloading a new CUDA library for my laptop’s graphics card, I managed to run the sound generation tensorflow script successfully.
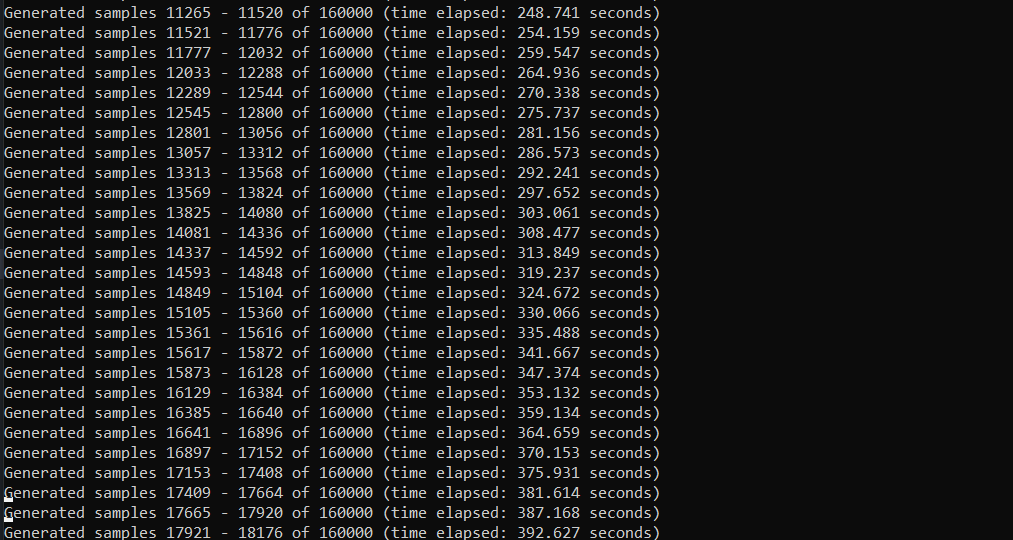
Above: My sound generation script running on my local environment
My first test was to generate 5 clips of 10 seconds on my laptop locally to compare. It took 3502.08 seconds to generate this at Epoch 12 of my model with a temperature of 0.95. This means it takes around an hour to generate 50 seconds worth of content. Meaning that even though I can run my model successfully on my computer, it would be best to continue using Google Colab to generate clips.
Narrowing Scope
The difficulty I ran into solving my Python environment and then the long time that it took my computer to generate the audio makes me feel that perhaps instead of a command line python script I should generate a python notebook that can run on more powerful computers remotely. I have seen this approach of avoiding running models remotely being used on other AI Art generation tools such as Midjourney and DALL-E (However I feel in those cases the intention is to maintain ownership of the model). I feel the upside of running a local environment is very minimal as with some small changes, power users can simply run the notebook on their own computers/ easily adapt the code to run on the command line instead of Colab.
In short, Changing my scope to a notebook fulfils my goal of creating an easy way to run my model as I think the wrapper is too much effort for something that is ultimately cosmetic.
Testing my Model

Above: The time it takes to generate 50 seconds of content on my local environment is roughly one hour. Sticking to the powerful computers at google.
As I have generated some sound using this model, lets look into what my computer has generated as I am actually a bit disappointed by my results.
All of the outputs are very quiet and do not meet my criteria of triggering an ASMR response.
As you can see the above response is very quiet here and almost inaudible, below is a spectrogram I took of the output and the notebook that I used to generate it.

Above: The notebook used to generate the spectrogram
Above: A spectrogram of my model, notice how we only go up to 8000 Hz as we have used a sample rate of 16kHz
Even though my model was silent to my ears, it was producing something clearly when looking at the spectrogram. To investigate further I generated a spectrogram of one of the slices of training data I used to compare:

Above: A chunk of my training data along with a spectogram using my Jupyter script, something is wrong
Firstly off the cuff, the file sizes are very different between my training data (11MB) and the output (312kb), this is probably due to the decreased sampling rate but it doesn’t explain why the above spectograph is so difficult to read which suggests that there is something wrong with my Jupyter notebook code as I would have expected the spectograph to look like the one below.

Above: What I got from putting the training data through this website
After messing around with a few different tutorials I eventually found a tutorial from dolby that allowed me to generate a normalized readable spectogram like the one above, which I then added some axis labels (And edited slightly to only sample 16kHz)
Now we can more accurately compare the training data and what was generated by the model
Above: fixed spectrograph generation code
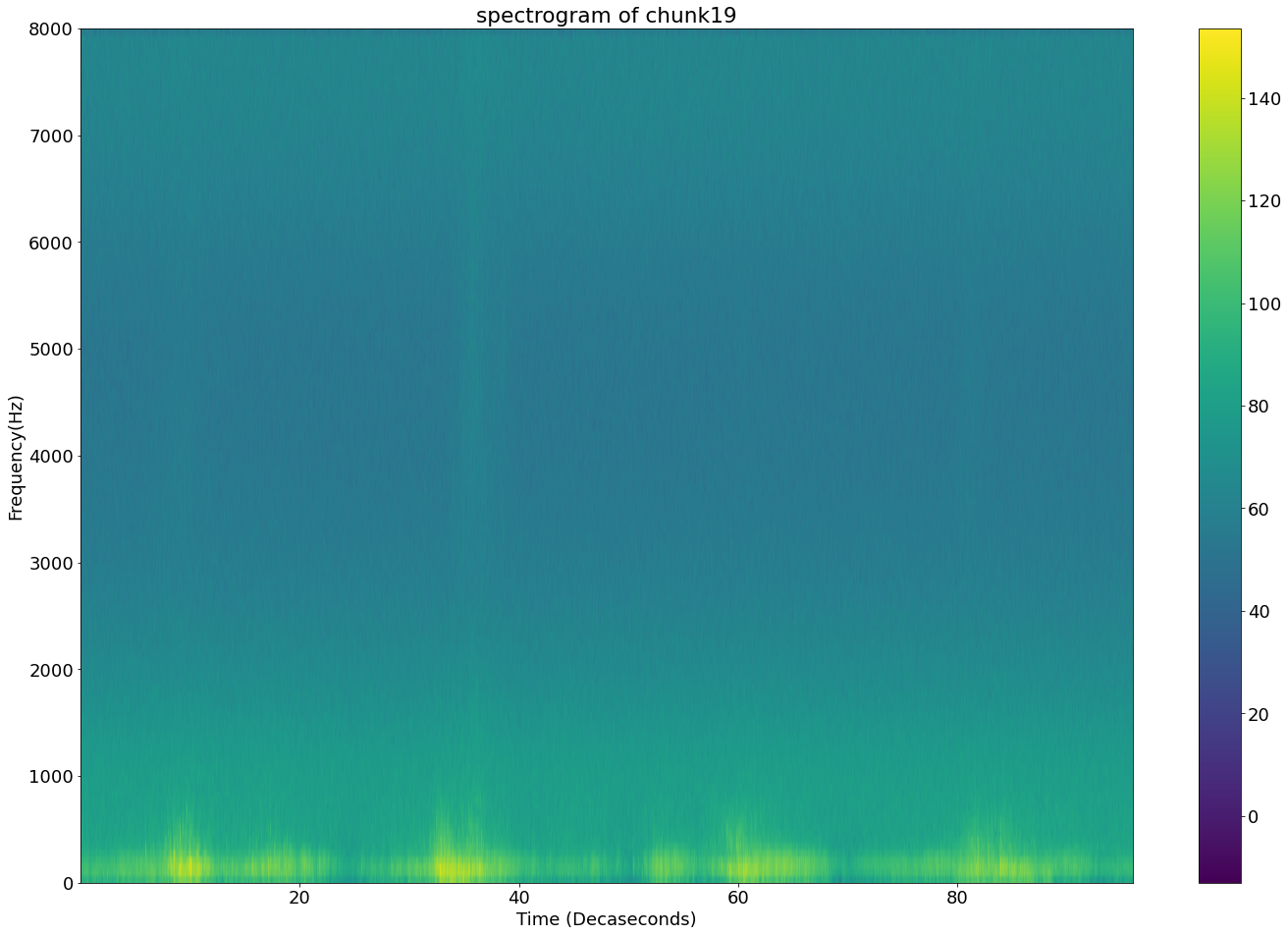
Above: Correct Spectrograph for training data chunk.

Above: The spectrograph data from my model when ran locally on my computer
The vertical lines remain the same between the two different spectrographs for my local model and these are not present in the training data (Also for some reason the generated audio appears to be breaking the spectrograph by not filling in the data close to 8kHz in every instance of vertical audio discontinuity). This could possibly be due to running the model locally but let me check an output from my colab model so I can be sure as in my previous post I expressed worry about model overfit and these artefacts could also be because of that.

Above: A spectrograph from an output generated online, note that this is from a significantly less trained model
Below: The output referenced in the above spectrograph, note how the content is audible compared to the more trained model
Looking at the lack of sudden vertical audio discontinuity in the above spectrograph and that it is from a model 10 generations younger, I can conclude that I have trained the model that I am using on my local device too much which is causing artefacts that are getting in the way of audio generation.
Conclusion
As I am moving away in this project from creating a local command line interface wrapper for my model primarily due to worry about machine processing power, my next goal is to find the best epoch to generate ASMR content from and then afterwards streamline the python notebook!